문제 링크: http://www.gurubee.net/lecture/2862
(내 댓글 참고)
[퀴즈] 목록과 함께 평균, 최대, 최소값 구하기
이번 퀴즈로 배워보는 SQL 시간에는 목록과 함께 평균, 최대, 최소값을 구하는 문제를 풀어본다. 지면 특성상 문제와 정답 그리고 해설이 같이 있다..
www.gurubee.net
문제 요약:
[표 1]의 각 일자별 수치 정보와 상태 코드 목록을 출력하고, 상태 코드(YN 칼럼)가 ‘Y’인 자료의 평균, 최댓값, 최솟값을 출력하세요.
마찬가지로 전체 자료에 대한 평균, 최댓값, 최솟값을 함께 출력하는 쿼리를 작성하세요.
또한 [표 2]의 결과를 도출하는 쿼리를 작성하세요. 평균값은 소수 2자리까지 표시하세요.
[STEP 1] YN 조건 상관없이 ROLLUP으로 V1/V2/V3/V4 평균 AVG 구해보기
쿼리)
ROLLUP을 이용하여 평균값 표시
WITH t
as (
SELECT '20140101' dt, 9 v1, 2 v2, 9 v3, 9 v4, 'N' yn FROM dual
UNION ALL SELECT '20140102', 9.9, 2.2, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140103', 9.8, 2.3, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140104', 9.7, 2.4, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140105', 9.6, 2.5, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140106', 9.5, 2.6, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140107', 9.4, 2.7, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140108', 9.3, 2.8, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140109', 9.2, 2.9, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140110', 9.1, 3.0, 5, 5, 'Y' FROM dual
)
SELECT DT
, AVG(V1)
, AVG(V2)
, AVG(V3)
, AVG(V4)
, YN FROM t
GROUP BY ROLLUP(yn, dt)
ORDER BY DT, YN
;
결과)
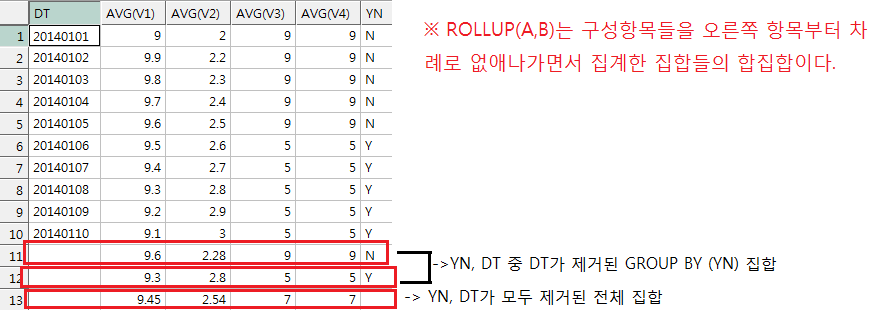
문제점
: 따로 조건 주지 않아 - YN이 N일 때, Y일 때의 결과가 다 나옴.
[STEP 2] HAVING 구절로 YN = 'Y'인 애들의 계산 값만 나오게 시도 (FAIL)
쿼리)
WITH t
as (
SELECT '20140101' dt, 9 v1, 2 v2, 9 v3, 9 v4, 'N' yn FROM dual
UNION ALL SELECT '20140102', 9.9, 2.2, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140103', 9.8, 2.3, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140104', 9.7, 2.4, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140105', 9.6, 2.5, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140106', 9.5, 2.6, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140107', 9.4, 2.7, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140108', 9.3, 2.8, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140109', 9.2, 2.9, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140110', 9.1, 3.0, 5, 5, 'Y' FROM dual
)
SELECT DT
, AVG(V1)
, AVG(V2)
, AVG(V3)
, AVG(V4)
, YN
FROM t
GROUP BY ROLLUP(YN, DT)
HAVING YN='Y'
ORDER BY DT, YN
;
결과)
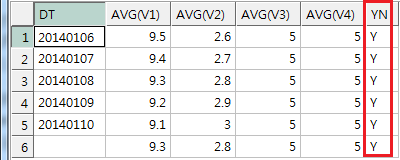
문제점
: 위 SELECT문도 영향이 감 - YN칼럼이 N인 애들은 아예 조회되지도 않음.
=> STEP 1으로 다시 롤백.
STEP 1 쿼리에서 어떤 조건을 더 준다면 값이 제대로 나오듯.
STEP 1의 구성된 집합들을 구별해 주는 함수 GROUPING 과 GROUPING_ID를 이용
[STEP 3] GROUPING, GROUPING_ID를 이용하여 YN = 'N'의 평균 제거
3-1)
GROUPING, GROUPING_ID를 써보자
WITH t
as (
SELECT '20140101' dt, 9 v1, 2 v2, 9 v3, 9 v4, 'N' yn FROM dual
UNION ALL SELECT '20140102', 9.9, 2.2, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140103', 9.8, 2.3, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140104', 9.7, 2.4, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140105', 9.6, 2.5, 9, 9, 'N' FROM dual
UNION ALL SELECT '20140106', 9.5, 2.6, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140107', 9.4, 2.7, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140108', 9.3, 2.8, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140109', 9.2, 2.9, 5, 5, 'Y' FROM dual
UNION ALL SELECT '20140110', 9.1, 3.0, 5, 5, 'Y' FROM dual
)
SELECT DT
, AVG(V1)
, AVG(V2)
, AVG(V3)
, AVG(V4)
, YN
, GROUPING(YN) GR_YN --YN 값이 그룹핑됐는지 여부를 나타냄. YN이 그룹핑돼 사라진 전체 집합의 경우 1
, GROUPING(DT) GR_DT --DT 값이 그룹핑됐는지 여부를 나타냄. DT가 그룹핑돼 YN만 남은 집합/전체 집합의 경우 1
, GROUPING_ID(YN,DT) GRID_YNDT
FROM t
GROUP BY ROLLUP(YN, DT)
ORDER BY DT, YN
;
♣추가 설명♣
+ GROUPING_ID(YN,DT) 말고 GROUPING(YN, DT) 사용 시 '인자의 개수가 부적절하다는' 에러가 남.
아래 GROUPING_ID의 속성을 이용하여 사용해야 함
GROUPING_ID(칼럼a, 칼럼 b [, …])
- GROUPING(칼럼a)||GROUPING(칼럼b)의 값을 2진수에서 10진수로 변환한 값
즉, GROUPING ID=1이라는 조건을 걸기 위해 위 SELECT문에 GROUPING, GROUPING_ID를 써줌 (밑에 쿼리 있음)
결과)
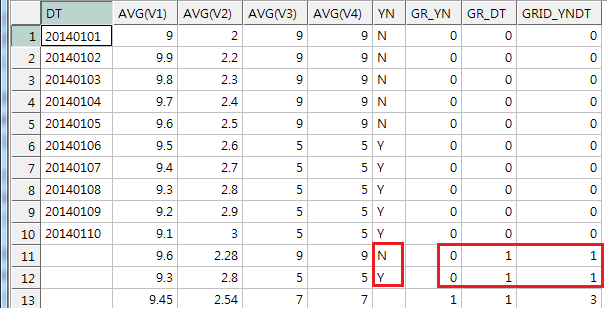
여기서 HAVING 조건 잘 쓰면 Y만 나오게 가능할 것 같지 않니?
3-2)
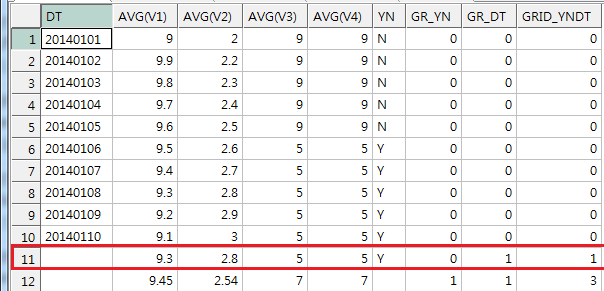
N 값이면서 GROUPING_ID(yn, dt)가 1인 조건 전체에 부정의 의미인 NOT을 붙여 해당 조건이 아닌 다른 자료만 뽑아내는 조건을 추가
HAVING NOT (YN='N' AND GROUPING_ID(YN,DT)=1)
결과)
'DATABASE > ORACLE' 카테고리의 다른 글
| [ORACLE SQL 문제] 경우의 수 구하기 (0) | 2020.03.04 |
|---|---|
| [ORACLE SQL 문제] 날짜별 모든 코드(빠진 데이터 없이)에 대한 자료 채우기 (0) | 2020.03.04 |
| [ORACLE SQL 문제] 일별 누적 접속자 통계 구하기 (0) | 2020.03.03 |
| [ORACLE SQL 문제] 여러 테이블 혼합해서 결과 표 도출하기 (0) | 2020.03.03 |
| [ORACLE SQL 문제] 연속된 숫자만 그룹핑하기 (0) | 2020.03.03 |
Comments